Overview
Gain a high-level understanding of how PipelineDP works as well as some of the foundational design decisions behind the project.
Note that this project is still experimental and is subject to change. At the moment we don’t recommend its usage in production systems as it’s not thoroughly tested yet. You can learn more in the Roadmap section.
Key concepts
The key definitions used in the documentation, code and examples are explained on this page.
Design overview
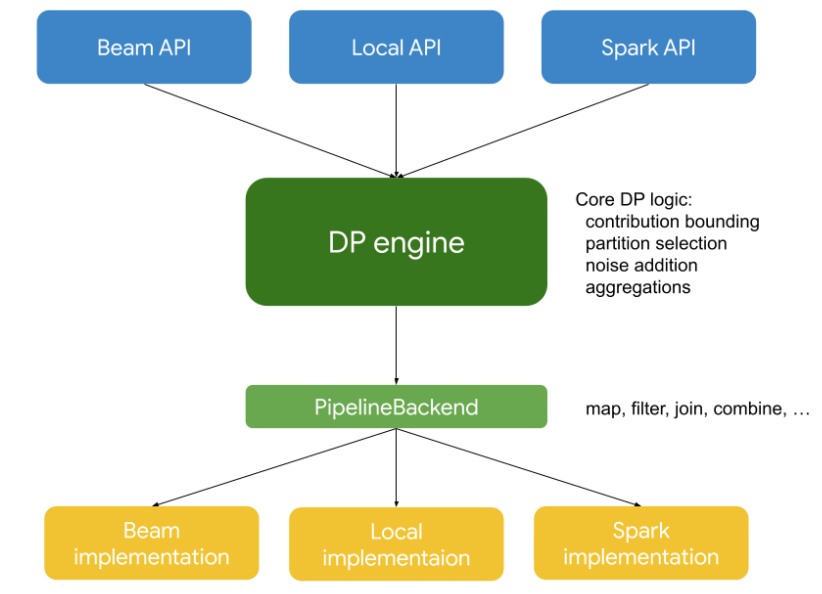
PipelineDP design enables execution on several data processing frameworks (including local execution), and is extensible to other frameworks. This is possible by implementing all DP logic in a framework-agnostic way, cleanly separated from how frameworks perform data processing.
Here’s how this works in detail:
DPEngine is the heart of PipelineDP. It’s a component that encapsulates all
differential privacy logic in a framework-agnostic way. Developers can use
DPEngine directly, however often they’ll prefer access via a set of
developer-facing APIs that resemble regular (non-private) APIs of the popular
frameworks.
PipelineBackend is an abstraction for low-level data processing operations
(map, join, combine, filter, etc.). The abstraction comes with several
framework-specific implementations that enable execution of PipelineDP on
Apache Beam, Apache Spark or even locally.
For more information about DP computation please check DP computations in pipelines reference doc.
Roadmap
A few high-level things we’re planning for future:
- Functionality:
- Adding more aggregation types (variance, percentiles, vector summation).
- Better integration with the Python ecosystem (e.g. dataframes).
- Utility:
- Using advanced composition methods (such as privacy loss distribution).
- Reliability:
- Rigorous statistical testing of differential privacy properties.